complaint_category_mapping <- list(
"Noise Related" = c(
"Noise - Residential", "Noise - Street/Sidewalk", "Noise - Commercial",
"Noise", "Noise - Vehicle", "Noise - Helicopter", "Noise - Park",
"Noise - House of Worship"
),
"Heat/Water/Gas Issues" = c(
"HEAT/HOT WATER", "Water System", "WATER LEAK", "PLUMBING",
"Water Leak", "Drinking Water", "Water Quality", "Water Maintenance",
"Water Drainage", "Drinking Water General", "Drinking Water Tank",
"Drinking Water Conservation", "Bottled Water", "DEP Sidewalk Condition",
"Non-Residential Heat", "Heat/Hot Water"
),
"Buildings and Housing" = c(
"PAINT/PLASTER", "DOOR/WINDOW", "FLOORING/STAIRS", "APPLIANCE",
"Elevator", "Lead", "SAFETY", "Indoor Air Quality", "Plumbing",
"Boilers", "Electrical", "ELEVATOR", "Asbestos", "Paint/Plaster",
"Door/Window", "OUTSIDE BUILDING", "Wood Pile", "Mold",
"Flooring/Stairs", "Appliance", "Scaffold Safety", "Electric",
"Unstable Building", "Window Guard", "Cooling Tower", "Peeling Paint",
"Facade Insp Safety Pgm", "Outside Building"
),
"Sanitation and Waste" = c(
"UNSANITARY CONDITION", "Dirty Condition", "Missed Collection",
"Residential Disposal Complaint", "Litter Basket Request",
"Commercial Disposal Complaint", "Litter Basket Complaint",
"Sanitation Worker or Vehicle Complaint", "Dumpster Complaint",
"Industrial Waste", "Seasonal Collection", "Institution Disposal Complaint",
"Transfer Station Complaint", "DSNY Internal"
),
"Street and Traffic Conditions" = c(
"Street Condition", "Traffic Signal Condition", "Street Light Condition",
"Sidewalk Condition", "Curb Condition", "Street Sign - Damaged",
"Street Sign - Missing", "Street Sign - Dangling", "Highway Condition",
"Highway Sign - Damaged", "Highway Sign - Missing", "Highway Sign - Dangling",
"Bridge Condition", "Tunnel Condition", "DEP Highway Condition",
"DEP Street Condition"
),
"Public Safety / Crime / Quality of Life" = c(
"Homeless Person Assistance", "Encampment", "Non-Emergency Police Matter",
"Drug Activity", "Graffiti", "Illegal Fireworks", "Panhandling",
"Animal-Abuse", "Violation of Park Rules", "Illegal Posting",
"Hazardous Materials", "Smoking", "Unleashed Dog", "Urinating in Public",
"Disorderly Youth", "Squeegee", "Quality of Life", "Face Covering Violation"
),
"Vehicle and Parking" = c(
"Illegal Parking", "Blocked Driveway", "Abandoned Vehicle",
"Derelict Vehicles", "Broken Parking Meter", "Municipal Parking Facility"
),
"Utilities and Power" = c(
"ELECTRIC", "Sewer", "Root/Sewer/Sidewalk Condition", "Radioactive Material",
"X-Ray Machine/Equipment", "Oil or Gas Spill"
),
"Pests and Animals" = c(
"Rodent", "Animal in a Park", "Unsanitary Pigeon Condition",
"Harboring Bees/Wasps", "Illegal Animal Kept as Pet", "Mosquitoes",
"Pet Shop", "Poison Ivy", "Illegal Animal Sold", "Unsanitary Animal Facility",
"Animal Facility - No Permit", "Unlicensed Dog", "Unsanitary Animal Pvt Property"
),
"Others / Miscellaneous" = c(
"General Construction/Plumbing", "Illegal Dumping", "GENERAL",
"Damaged Tree", "Maintenance or Facility", "New Tree Request",
"For Hire Vehicle Complaint", "Overgrown Tree/Branches", "Consumer Complaint",
"Vendor Enforcement", "Building/Use", "Obstruction", "Air Quality",
"Dead/Dying Tree", "Dead Animal", "Street Sweeping Complaint",
"Taxi Complaint", "Lost Property", "Outdoor Dining",
"Real Time Enforcement", "Mobile Food Vendor", "Bike/Roller/Skate",
"Chronic", "Special Projects Inspection Team (SPIT)", "Illegal Tree Damage",
"Electronics Waste Appointment", "Emergency Response Team (ERT)",
"Food Poisoning", "Smoking or Vaping", "Day Care", "Standing Water",
"Investigations and Discipline (IAD)", "Remaining Taxi Report",
"E-Scooter", "BEST/Site Safety", "Indoor Sewage", "For Hire Vehicle Report",
"Uprooted Stump", "Green Taxi Complaint", "Ferry Inquiry", "Ferry Complaint",
"Beach/Pool/Sauna Complaint", "Tattooing", "Plant", "Bus Stop Shelter Placement",
"LinkNYC", "Bus Stop Shelter Complaint", "Posting Advertisement",
"Taxi Compliment", "AHV Inspection Unit", "Adopt-A-Basket",
"Cranes and Derricks", "Recycling Basket Complaint", "Found Property",
"Incorrect Data", "Bike Rack", "Special Natural Area District (SNAD)",
"Public Toilet", "Dept of Investigations", "Lifeguard", "Special Operations",
"Dispatched Taxi Complaint", "Boiler", "Bench", "Building Condition",
"Taxi Licensee Complaint", "Retailer Complaint", "Calorie Labeling",
"ZTESTINT", "Public Payphone Complaint", "FHV Licensee Complaint",
"Wayfinding SNW", "Leaning", "Bar", "Building Marshal's Office",
"Building Marshals office", "DOB Posted Notice or Order",
"Construction Safety Enforcement", "Tanning", "Executive Inspections",
"Internal", "Code", "Private School", "Vaccine Mandate Non-Compliance",
"Dispatched Taxi Compliment", "SRDE", "Stalled Sites",
"Sustainability Enforcement", "Trans Fat", "Food Establishment",
"Sewer Maintenance", "Bike Rack Condition", "Construction Lead Dust"
)
)
# Create a long-format data frame
complaint_mapping_df <- data.frame(
complaint_type = unlist(complaint_category_mapping),
category = rep(names(complaint_category_mapping),
sapply(complaint_category_mapping, length)),
stringsAsFactors = FALSE
)
rownames(complaint_mapping_df) <- NULL
map_complaint_to_category <- function(complaint_type) {
for (category in names(complaint_category_mapping)) {
if (complaint_type %in% complaint_category_mapping[[category]]) {
return(category)
}
}
return("Others / Miscellaneous")
}
# Apply the mapping to create complaint_bucket column
df_clean_final <- df_clean_final |>
mutate(complaint_bucket = sapply(complaint_type, map_complaint_to_category))
saveRDS(df_clean_final, "df_final.rds")
# Save updated data frame
complaint_bucket_counts <- df_clean_final |>
count(complaint_bucket, sort = TRUE)
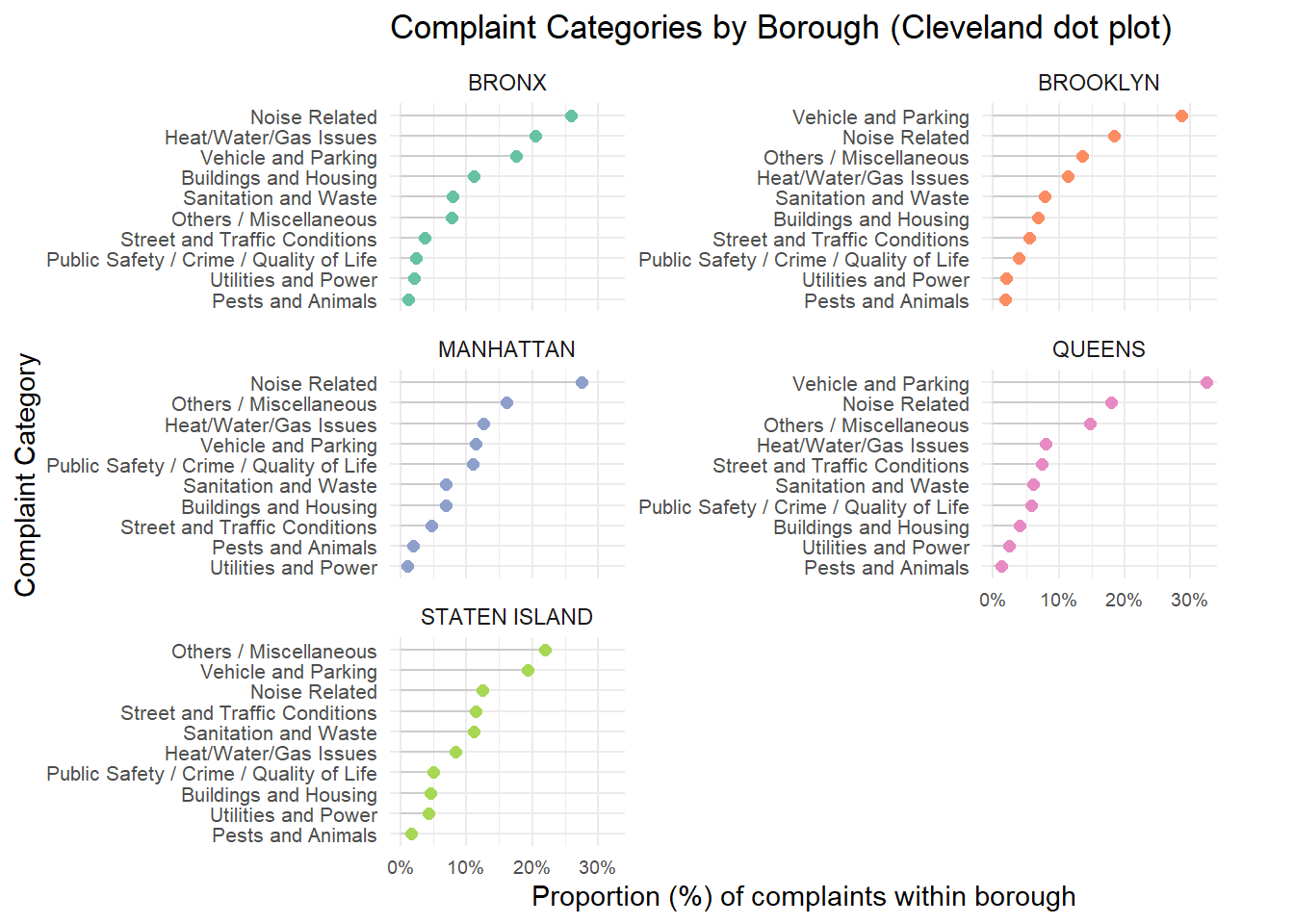
complaint_bucket_borough <- df_clean_final |>
group_by(borough, complaint_bucket) |>
summarise(count = n(), .groups = "drop") |>
group_by(borough) |>
mutate(
total_borough = sum(count),
proportion = count / total_borough * 100
) |>
ungroup()
print(complaint_bucket_borough)